| Date | Authors | Affiliations |
|---|---|---|
| June 2025 | Murtaza Nazir | Independent researcher |
| Matthew Finlayson | DILL & INK Labs, University of Southern California | |
| Jack Morris | Cornell University | |
| Xiang Ren | INK Lab, University of Southern California | |
| Swabha Swayamdipta | DILL Lab, University of Southern California |
TL;DR: We trained a language model inverter to guess secret hidden prompts from language model outputs, and it absolutely crushes the competition. How? By representing language model outputs the right way.
When interacting with an AI model via an API, you never know exactly what prompt is being sent to the model. Providers routinely modify user prompts—prepending secret system messages, or making other changes—sometimes for security reasons, or to protect trade secrets. A whole cottage industry has emerged around reverse engineering these “secret” system messages from language model outputs.
While early methods for stealing prompts were themselves prompt-based (e.g., asking the model to repeat the hidden prompt), neural methods for prompt recovery are now emerging. This approach—known as language model inversion [1]—trains a model (known as an inverter) to guess hidden prompts by looking at the outputs from a target model. Compared to prompting attacks, inversion attacks can be harder to detect and defend against, since they can work even if the model doesn’t repeat the prompt.
| Secret prompt | Output (Llama 2 Chat) | Inverter guess |
|---|---|---|
| Tell me about a time you felt afraid | I’m just an AI, I don’t have personal experiences or emotions, including fear. | Tell me about a time you felt afraid |
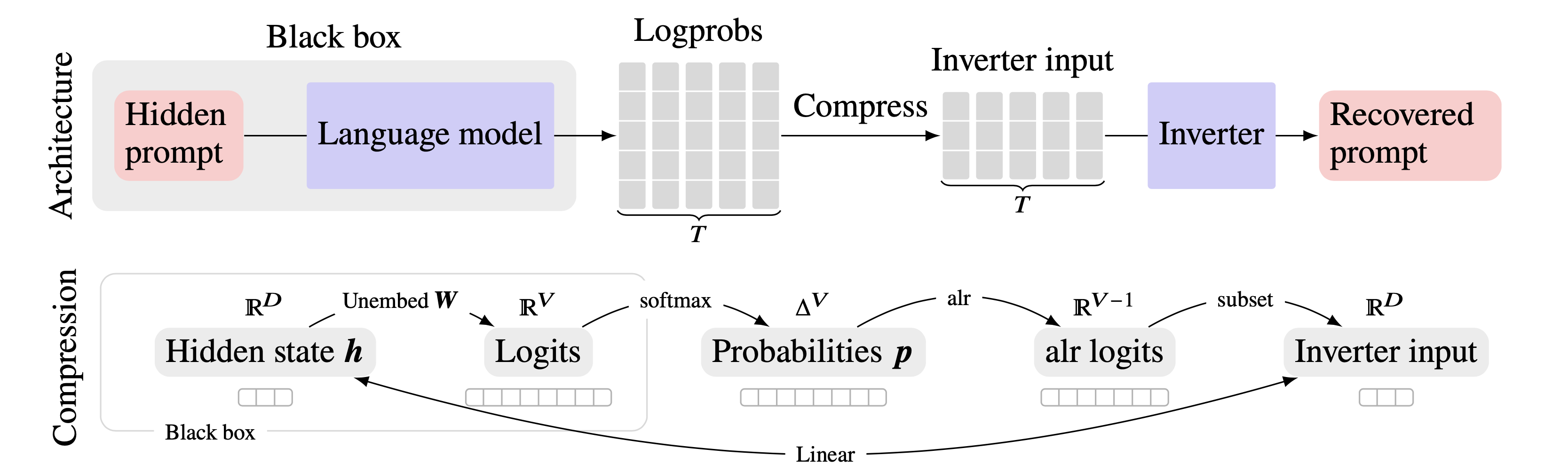
So far, language model inversion’s success has been limited: exact prompt recovery rates rarely exceed 25%. Looking at the existing methods, we observed that none fully exploit the rich information hidden in the model outputs. Prior approaches supply the inverter with either the text output [2] or the next token logprobs from just one generation step1 [1].
The chief bottleneck in prior work is the size of the target model output/inverter input. Next-token logprobs are information-rich, but enormous: each generation step yields a vector as large as the entire model vocabulary, which ranges from 35,000 to over 200,000 tokens. Meanwhile, clues about the hidden prompt may only surface after many generation steps, giving an advantage to text-based inverters. Naïvely, combining these approaches by using full logprob outputs over multiple generation steps would result in an impractically large inverter input size of \(|\text{vocab}|\times|\text{sequence}|.\)
We overcome this by taking advantage of a mathematical property of modern transformers: their outputs are subject to low-dimensional linear constraints [3]. Specifically, for a small value of \(d\ll|\text{vocab}|\), there is a set of \(d\) tokens whose logprobs linearly encode all the information about all the other token logprobs.2 Therefore, we only collect logprobs for these tokens, discarding the rest without loss of information. Thus we bring our inverter input down to a reasonable size of \(d\times|\text{sequence}|\).
The result is a remarkable improvement over previous language model inversion methods. In the table below, we highlight one of our favorite results, where we compare our inverter—called prompt inversion from logprob sequences, or PILS—to earlier prompt recovery approaches, as measured by BLEU, exact match, and token F1 between the actual and recovered prompts. This particular evaluation uses the held-out Alpaca Code dataset.
| Inverter | BLEU | Exact match | Token F1 |
|---|---|---|---|
| Prompt [4] | 14.2 | 0.0 | 36.8 |
| Logit2Text [1] | 34.6 | 2.5 | 65.2 |
| Logit2Text++ | 44.4 | 8.2 | 73.9 |
| Output2Prompt [2] | 61.2 | 16.9 | 80.3 |
| PILS (ours) | 85.0 | 60.5 | 93.1 |
We invite you to browse the results from our paper, which show that our method yields large, consistent, gains across all datasets and metrics.
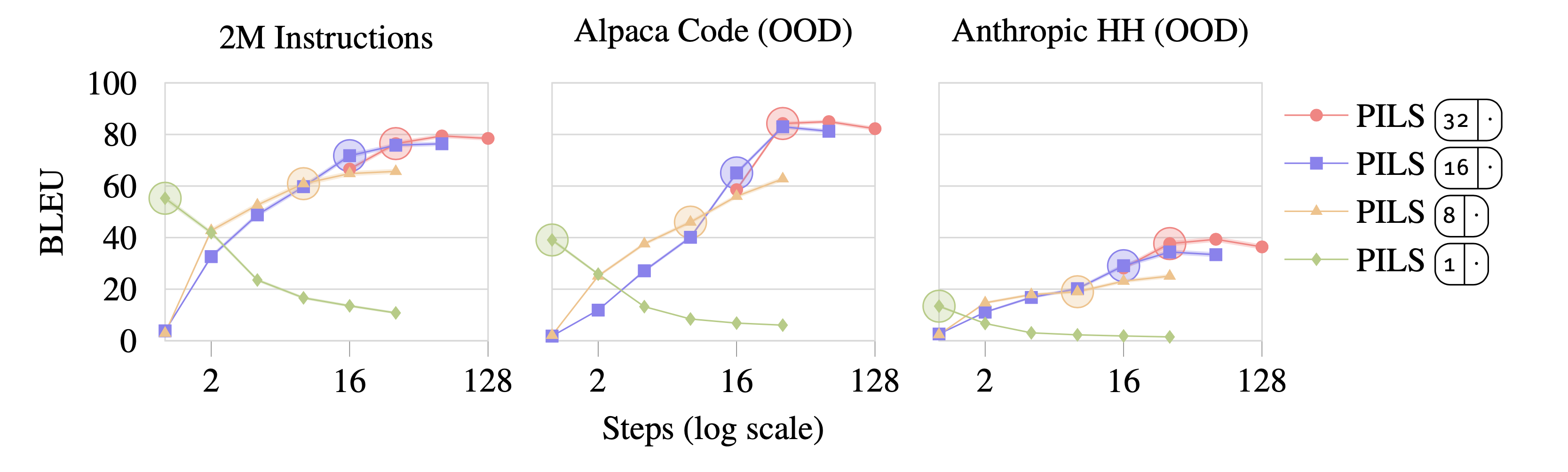
Curiously, we find that our model generalizes in an unexpected way: when we increase the sequence length of the target model outputs at test time, our inverter’s performance continues to improve, even after the length surpasses what the inverter saw during training.
We we believe that research on prompt recover attacks is vital for the community. Prompts should not be considered secrets [4], and forensic tools for inspecting hidden prompts helps keep API providers accountable. Imagine if an API provider secretly instructed their model to introduce subtle bugs or backdoors in users’ code! This line of work is crucial for promoting transparency, safety, and good practices in the community.
@misc{nazir2025betterlanguagemodelinversion,
title={Better Language Model Inversion by Compactly Representing Next-Token Distributions},
author={Murtaza Nazir and Matthew Finlayson and John X. Morris and Xiang Ren and Swabha Swayamdipta},
year={2025},
eprint={2506.17090},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2506.17090},
}Language models generate text one token (\(\approx\)word) at a time. Every model has a vocabulary of tokens, and for each step in the generation process, they report the (log)probability of each token being the next token in the generation.↩︎
In practical settings, almost any collection of \(d\) tokens will satisfy this property.↩︎